 IhaveBB
IhaveBB  匿名
匿名  IhaveBB
IhaveBB AI摘要:JavaEE线程池是一种线程管理技术,用于减少线程创建和销毁的资源损耗,提高程序性能。线程池通过工厂模式创建,有多种类型,如固定大小、可缓存、单线程、定时执行等。创建线程池时,可以设置核心线程数、最大线程数、存活时间、任务队列、线程工厂和拒绝策略等参数。任务队列有直接提交、有界和无界三种,拒绝策略包括抛出异常、调用者运行、丢弃任务等。自定义拒绝策略需实现RejectedExecutionHandler接口。阿里巴巴推荐使用ThreadPoolExecutor创建线程池,以避免资源耗尽风险。
Powered by AISummary.
JavaEE线程池
一.简介
1.1什么是线程池
在JAVA中,虽然创建和使用一个线程非常容易,但是由于创建线程需要使用使用一定的资源,在高并发高负载的情况下,频繁的创建和销毁线程会大量小号CPU和内存资源,对程序性能会造成很大的影响,为了解决这一问题,线程池应运而生。
线程池是一种利用池化思想来实现的线程管理技术
使用类似思想的技术还有MySQL的连接池,JVM的字符串常量池等
线程池最大的好处就是减少每次启动、销毁线程的损耗并且方便管理这些资源
同时,阿里巴巴在其《Java开发手册》中也强制规定:线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
二.线程池的介绍
2.1 线程池的创建方法
线程池的创建方法一共有七种,但总体分为两类
- 通过
Executors工厂类创建. 创建方式比较简单, 但是定制能力有限. - 通过
ThreadPoolExecutor创建. 创建方式比较复杂, 但是定制能力强
2.1.1 如何“new”一个线程池
那么我们如何创建一个线程池呢?
线程池对象不是咱们直接通过new来创建的。而是通过了一个称专门的方法,反回了一个线程池对象
下面展示了两个创建方法,图一为正确方法,图二为错误示例


那么,这种创建线程池的方法叫什么呢?
我们称这种方式为工厂模式(设计模式),工厂模式是用来给构造方法填坑的,因为构造方法存在着一定的局限性。那么这种局限性是什么呢?
构造方法的局限性
我们考虑有一个类,期望使用笛卡尔坐标系来构建对象(极坐标)
♾️ java 代码: public Point(int x, int y){}
public Point(int r, int a){}但是这两个方法并没有构成重载,就会编译失败。
很多时候我们构造一个对象希望有多种构造方式,就需要使用多个版本的构造方法来实现
但是构造方法要求方法的名字必须是类名,不同的构造方法只能通过重载来区分
工厂设计模式的优势
使用工厂设计模式就能解决这个问题。
使用普通的方法来代替构造方法完成初始化的工作.
普通方法就可以使用方法的名字来区分了,也就不受到重载规则的约束了.
工厂设计模式的示例
♾️ java 代码:class PointFactory(){
public static Point makePointByXY(double x, double y){
Point p = new Point();
p.setX(X);
P.setY(Y);
return p;
}
public static Point makePointByA(double r,double a){
//写一个方法
}
}2.1.2线程池的类型
线程池的创建方式总共包含以下 7 种(其中 6 种是通过 Executors 创建的,1 种是通过 ThreadPoolExecutor 创建的):
其实Executors本质上都是对ThreadPoolExecutor进行的封装
Executors.newFixedThreadPool(int nThreads): 创建一个固定大小的线程池,可以控制并发的线程数,超出的任务会在队列中等待。Executors.newCachedThreadPool(): 创建一个可缓存的线程池,如果线程数超过处理所需,会缓存一段时间后回收多余的线程,如果线程数不够,则新建线程。Executors.newSingleThreadExecutor(): 创建一个单个线程的线程池,保证任务按照先进先出的顺序执行。Executors.newScheduledThreadPool(int corePoolSize): 创建一个可以执行延迟任务的线程池,用于定时执行任务。Executors.newSingleThreadScheduledExecutor(): 创建一个单线程的可以执行延迟任务的线程池,也用于定时执行任务。Executors.newWorkStealingPool(): 创建一个工作窃取线程池,允许任务执行的顺序不确定,通常用于高度并发的场景。这个方法是在 JDK 1.8 中引入的。ThreadPoolExecutor:最原始的创建线程池的方式,它包含了 7 个参数可供设置
单线程池的意义: 虽然 newSingleThreadExecutor 和newSingleThreadScheduledExecutor** 是单线程池,但提供了工作队列,生命周期管理,工作线程维护等功能。
2.2 ThreadPoolExecutor
2.2.1创建方式
首先,我们看一下最原始创建线程池的方式ThreadPoolExecutor
import java.util.Collection;
import java.util.concurrent.*;
public class Demo1 {
public static void main(String[] args) {
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5,10,100,TimeUnit.SECONDS,new LinkedBlockingQueue<>(10));
for(int i = 0; i < 10; i++) {
int index = i;
threadPool.execute(() -> {
System.out.println(index + " 线程名:" + Thread.currentThread().getName());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}2.2.2参数介绍
ThreadPoolExecutor 最多可以设置 7 个参数:
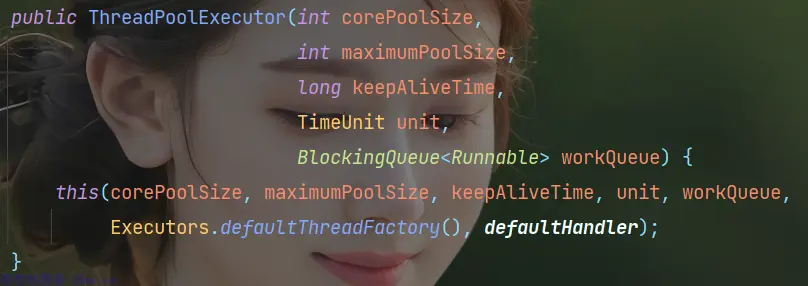
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)接下来我们详细看一下七个参数具体代表什么
corePoolSize:核心线程数,线程池中始终存活的线程数。
or:正式员工的数量. (正式员工, 一旦录用, 永不辞退)
maximumPoolSize: 最大线程数,线程池中允许的最大线程数,当线程池的任务队列满了之后可以创建的最大线程数。
or:正式员工 + 临时工的数目. (临时工: 一段时间不干活, 就被辞退).
keepAliveTime:最大线程数可以存活的时间,当线程中没有任务执行时,最大线程就会销毁一部分,最终保持核心线程数量的线程。
or:临时工允许的空闲时间.
unit:单位是和参数 3 存活时间配合使用的,合在一起用于设定线程的存活时间。参数 keepAliveTime 的时间单位有以下 7 种可选:
- TimeUnit.DAYS:天
- TimeUnit.HOURS:小时
- TimeUnit.MINUTES:分
- TimeUnit.SECONDS:秒
- TimeUnit.MILLISECONDS:毫秒
- TimeUnit.MICROSECONDS:微妙
- TimeUnit.NANOSECONDS:纳秒
workQueue:阻塞队列,用来存储线程池等待执行的任务,均为线程安全。它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种,包含以下 7 种类型:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
- SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
- DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
较常用的是
LinkedBlockingQueue和Synchronous,线程池的排队策略与 BlockingQueue 有关- threadFactory:创建线程的工厂, 参与具体的创建线程工作.
handler:拒绝策略,拒绝处理任务时的策略,系统提供了 4 种可选:
or:拒绝策略, 如果任务量超出公司的负荷了接下来怎么处理.
- AbortPolicy:超过负荷, 直接抛出异常.
- CallerRunsPolicy:调用者负责处理
- DiscardOldestPolicy:丢弃队列中最老的任务.
- DiscardPolicy:丢弃新来的任务.
默认策略为 AbortPolicy
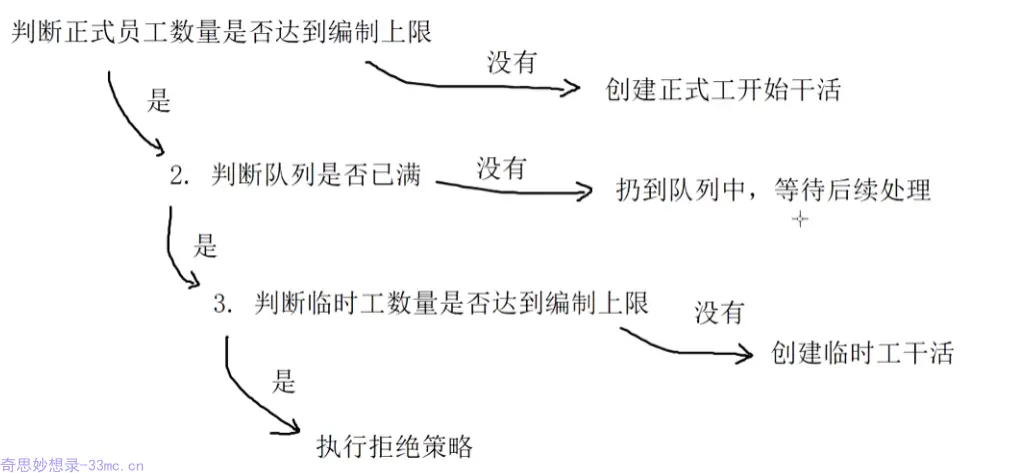
2.2.3线程池执行流程
ThreadPoolExecutor 关键节点的执行流程如下:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
当线程数大于等于核心线程数,且任务队列已满:若线程数小于最大线程数,创建线程;若线程数等于最大线程数,抛出异常,拒绝任务。

2.3 Executors.newFixedThreadPool
FixedThreadPool:创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待
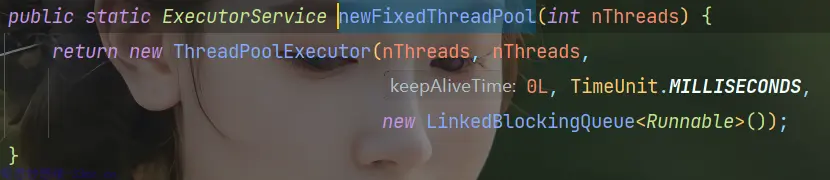
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}- corePoolSize 与 maximumPoolSize 相等均为nThreads即为线程池大小固定
- keepAliveTime = 0 该参数默认对核心线程无效,而
FixedThreadPool全部为核心线程; - workQueue 为
LinkedBlockingQueue(无界阻塞队列),队列最大值为Integer.MAX_VALUE。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo2 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(2);
Runnable runnable = new Runnable(){
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程:" + Thread.currentThread().getName());
}
};
threadPool.submit(runnable);
threadPool.submit(runnable);
threadPool.submit(runnable);
threadPool.submit(runnable);
System.out.println("主线程结束");
}
}
上述代码:创建了一个有2个线程的线程池,但一次给它分配了4个任务,每次只能执行2个任务,所以,得执行两次。
注:submit()方法和execute()方法都是执行任务的方法。它们的区别是:submit()方法有返回值,而execute()方法没有返回值。
在这里我们又引出了一个问题,线程数量设置多少最为合适呢?
其实这个问题网上有很多回答,但无论说什么,那都是不正确的.
因为在没有接触到实际项目的代码之前,是无法确定的.
一个线程执行的代码主要有两类:
- CPU密集型,代码里主要的逻辑实在进行算术运算/逻辑判断
- IO密集型,代码里主要进行IO操作
假设一个线程的所有代码都是 cpu 密集型代码,这个时候,线程池的数量不应该超过 N设置的比 N 更大,这个时候,也无法提高效率了.(cpu 负载满了)此时更多的线程反而增加调度的开销
假设一个线程的所有代码都是 IO密集的.这个时候不吃 CPU,此时设置的线程数,就可以是超过 N.较大的值个核心可以通过调度的方式,来并发执行
代码不同,线程池的线程数目设置就不同.
无法知道一个代码,具体多少内容是 cpu 密集,多少内容是 IO 密集.
2.4 Executors.newCachedThreadPool
CachedThreadPool:创建一个可缓存的线程池,若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程。
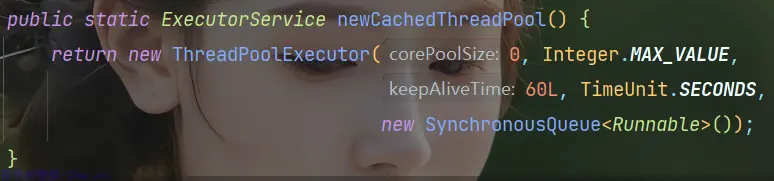
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- corePoolSize = 0,maximumPoolSize = Integer.MAX_VALUE,即线程数量几乎无限制;
- keepAliveTime = 60s,线程空闲 60s 后自动结束
- workQueue 为 SynchronousQueue 同步队列,这个队列类似于一个接力棒,入队出队必须同时传递,因为 CachedThreadPool 线程创建无限制,不会有队列等待,所以使用 SynchronousQueue
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Demo3 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 100; i++) {
threadPool.execute(() -> {
System.out.println("线程:" + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
2.5 Executors.newSingleThreadExecutor
SingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执行顺序。
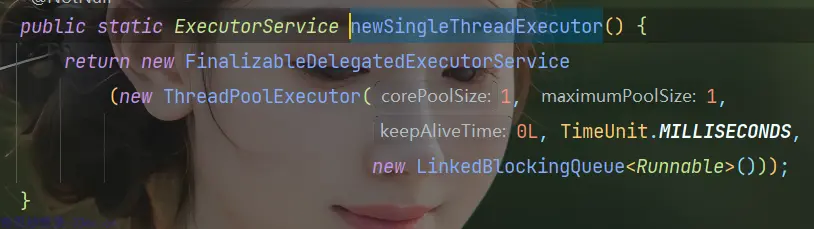
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}- corePoolSize = 1,maximumPoolSize = 1,即线程数量只能为1;
- keepAliveTime = 0
- workQueue 为
LinkedBlockingQueue(无界阻塞队列),队列最大值为 1。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Demo4 {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
int count = i;
threadPool.execute(() -> {
System.out.println(count + ":任务被执行");
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
2.6 Executors.newScheduledThreadPool
ScheduledThreadPool:创建一个可以执行延迟任务的线程池。
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class Demo5 {
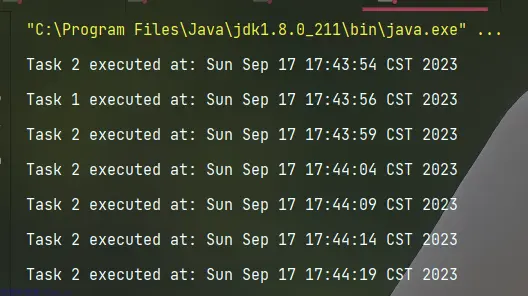
public static void main(String[] args) {
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(2);
// 安排任务在一定的延迟后执行
scheduledExecutorService.schedule(() -> {
System.out.println("Task 1 executed at: " + new Date());
}, 2, TimeUnit.SECONDS);
// 安排任务在固定的时间间隔内重复执行
scheduledExecutorService.scheduleAtFixedRate(() -> {
System.out.println("Task 2 executed at: " + new Date());
}, 0, 5, TimeUnit.SECONDS);
// 在此示例中,Task 1将在2秒后执行一次,而Task 2将每隔5秒执行一次
// 等待一段时间后关闭ScheduledExecutorService
}
}
2.7 newSingleThreadScheduledExecutor
♾️ java 代码:import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
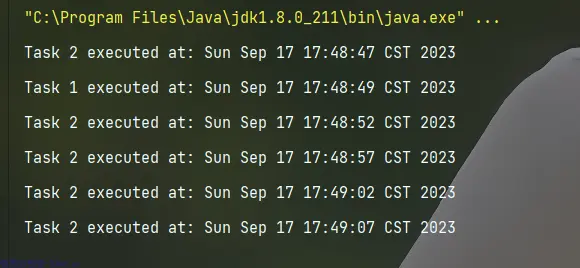
public class Demo6 {
public static void main(String[] args) {
ScheduledExecutorService singleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
// 安排任务在一定的延迟后执行
singleThreadScheduledExecutor.schedule(() -> {
System.out.println("Task 1 executed at: " + new Date());
}, 2, TimeUnit.SECONDS);
// 安排任务在固定的时间间隔内重复执行
singleThreadScheduledExecutor.scheduleAtFixedRate(() -> {
System.out.println("Task 2 executed at: " + new Date());
}, 0, 5, TimeUnit.SECONDS);
// 在此示例中,Task 1将在2秒后执行一次,而Task 2将每隔5秒执行一次
// 等待一段时间后关闭SingleThreadScheduledExecutor
}
}
2.8 newWorkStealingPool
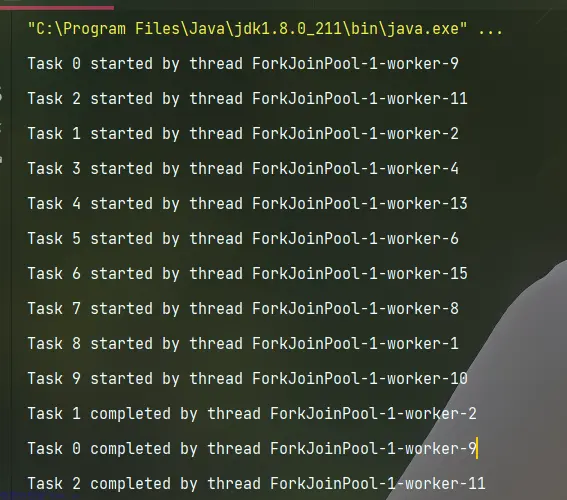
NewWorkStealingPoo0l:创建一个抢占式执行的线程池(任务执行顺序不确定),注意此方法只有在 JDK 1.8+ 版本中才能使用。它是一种特殊类型的线程池,适用于处理计算密集型任务。工作窃取线程池会自动将任务分配给可用线程,并允许线程之间窃取任务以保持高效的利用。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Demo7 {
public static void main(String[] args) {
// 创建工作窃取线程池
ExecutorService threadPool = Executors.newWorkStealingPool();
// 提交一些任务
for (int i = 0; i < 10; i++) {
final int taskId = i;
threadPool.submit(() -> {
try {
System.out.println("Task " + taskId + " started " + Thread.currentThread().getName());
// 模拟任务执行
TimeUnit.SECONDS.sleep(2);
System.out.println("Task " + taskId + " completed " + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
// 等待一段时间,以确保任务有足够的时间完成
try {
TimeUnit.SECONDS.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 关闭线程池
threadPool.shutdown();
}
}
二.任务队列
在上面2.2.2中的workQueue里,我们提到一共有七种任务队列。通常使用这三种任务队列,即直接提交队列(SynchronousQueue)、有界任务队列(ArrayBlockingQueue)和无界任务队列(LinkedBlockingQueue),接下来我们详细介绍下这三种队列。
直接提交队列 (SynchronousQueue):
- 这是一个没有容量的队列,它用于在线程池的任务提交和执行之间的直接传递。
- 每次提交一个任务,都会尝试立即执行它,如果没有空闲线程,则会尝试创建新线程。
- 如果已经有线程数达到
maximumPoolSize,而且队列没有足够的空间,那么线程池将拒绝接收新的任务并且采取拒绝策略(例如抛出异常)。
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 100, TimeUnit.SECONDS, new SynchronousQueue<>());有界任务队列 (ArrayBlockingQueue):
- 这是一个有容量限制的队列,它用于缓存等待执行的任务。
- 当线程池的线程数量小于
corePoolSize时,新任务会创建新线程并立即执行。 - 当线程池的线程数量达到
corePoolSize时,新任务会被放入队列中等待执行。 - 如果队列已满,但线程数还未达到
maximumPoolSize,那么将会创建新线程来执行任务。 - 如果线程数已经达到
maximumPoolSize,则根据设置的拒绝策略处理新的任务。
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10));无界任务队列 (LinkedBlockingQueue):
- 这是一个无限容量的队列,它用于缓存等待执行的任务。
- 线程池的线程数量将保持在
corePoolSize的数量,不会超过。 - 新任务会被放入队列中等待执行,而不会创建超出
corePoolSize的新线程。 maximumPoolSize参数在这种情况下是无效的,因为线程数不会超过corePoolSize。
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());选择适当的任务队列类型取决于你的应用程序需求和性能要求。如果你需要精确控制线程数和任务执行,有界队列可能更合适。如果你想最大程度地利用系统资源,无界队列可能更适合。直接提交队列通常在需要立即执行任务的情况下使用。要记住,不同的任务队列类型可能会影响到线程池的行为和性能,所以需要根据具体的场景来选择。
四.线程拒绝策略
当使用线程池来管理并发任务时,有时候任务提交的速度可能会超过线程池的处理能力,这时就需要一种机制来处理这种情况。线程池的拒绝策略(Rejection Policy)提供了一种处理方式,用于定义当任务无法被接受和处理时应该采取的措施。
在 Java 中,线程池的拒绝策略由 RejectedExecutionHandler 接口定义,它有几种内置的实现,常见的包括:
- AbortPolicy(抛弃策略):这是默认的拒绝策略,当任务无法被接受时,会抛出
RejectedExecutionException异常。 - CallerRunsPolicy(调用者运行策略):当任务无法被接受时,会在当前线程中执行该任务,而不会抛出异常。这样可以降低任务提交者的速度,但可能会影响到整体性能。
- DiscardPolicy(丢弃策略):当任务无法被接受时,将简单地丢弃该任务,不做任何处理。
- DiscardOldestPolicy(丢弃最旧策略):当任务无法被接受时,会丢弃队列中最旧的任务,然后尝试重新提交当前任务。
让我们结合一个示例来深入了解这些拒绝策略的工作方式。我们使用 ThreadPoolExecutor 类来创建一个线程池,并演示使用不同的拒绝策略:
import java.util.Date;
import java.util.concurrent.*;
public class ThreadPoolRejectionPolicyDemo {
public static void main(String[] args) {
// 创建线程池,核心线程数为1,最大线程数为1,队列容量为1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1, 100,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(1));
// 设置拒绝策略为 CallerRunsPolicy
threadPool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 任务
Runnable runnable = () -> {
System.out.println("当前任务被执行, 执行时间: " + new Date() +
" 执行线程: " + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
};
// 开启4个任务
for (int i = 0; i < 4; i++) {
threadPool.execute(runnable);
}
// 关闭线程池
threadPool.shutdown();
}
}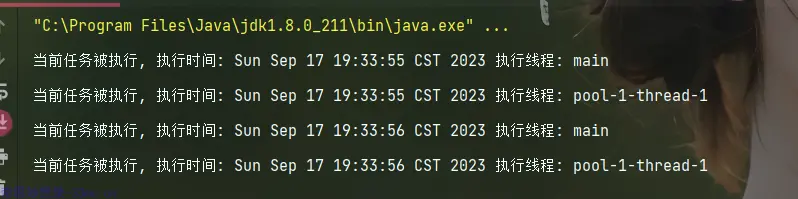
在上面的示例中,我们创建了一个核心线程数和最大线程数都为1的线程池,并将队列容量设置为1。这意味着线程池最多只能同时执行一个任务,同时任务队列只能容纳一个等待执行的任务。
然后,我们将拒绝策略设置为 CallerRunsPolicy,这意味着当有任务无法被接受时,当前线程(任务提交者的线程)将运行该任务,而不会抛出异常。
最后,我们提交了4个任务给线程池,但由于线程池的容量有限,只有一个任务能够立即执行,其余的任务将被线程池按照拒绝策略处理。在这个示例中,我们看到被拒绝的任务被调用者线程(主线程)执行,而不是抛出异常。
五.自定义拒绝策略
自定义拒绝策略需要实现 RejectedExecutionHandler 接口,该接口有一个方法 rejectedExecution,在任务被拒绝执行时被调用。下面是一个简单的示例:
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
public class Demo9 implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 自定义拒绝策略的处理逻辑
System.out.println("任务被拒绝执行:" + r.toString());
// 可以根据需求执行其他操作,例如记录日志、重新提交任务等
}
}或者可以这样使用匿名内部类
♾️ java 代码:RejectedExecutionHandler customRejectionHandler = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 自定义拒绝策略的处理逻辑
System.out.println("任务被拒绝执行:" + r.toString());
// 在这里你可以执行自定义的处理操作,比如记录日志或重新提交任务
}
};
那么如何把自定义拒绝策略应用到我们的线程池呢?
我们只需要在最后加入我们的自定义策略名称即可。
♾️ java 代码:ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
2, // 核心线程数
4, // 最大线程数
10, // 线程空闲时间
TimeUnit.SECONDS, // 时间单位
new LinkedBlockingQueue<>(2), // 任务队列容量为2
customRejectionHandler // 自定义拒绝策略
);六.模拟实现线程池
♾️ java 代码:import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class MyThreadPool{
private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1000); // 1000 是队列的容量
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
public MyThreadPool(int n ) {
for(int i = 0; i < n; i++){
Thread t = new Thread(() -> {
try {
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
}
public static void main(String[] args) throws InterruptedException {
MyThreadPool myThreadPool = new MyThreadPool(10);
for (int i = 0; i < 1000; i++) {
int id = i;
myThreadPool.submit(() -> {
System.out.println("执行任务:" + id);
});
}
}
}在这个代码中,不知道大家有没有注意到一个问题,
♾️ java 代码: for (int i = 0; i < 1000; i++) {
int id = i;
myThreadPool.submit(() -> {
System.out.println("执行任务:" + id);
});
}在这个代码里打印执行任务时,没有直接使用i,而是新创建了一个id来表示i.
这是因为i是在匿名内部类中的,但是部落了外部变量中的i
变量捕获只能捕获final,所以我们需要新建一个id,就能让其捕获的是ID不是I了
七.如何选择线池
我们来看看阿里巴巴《Java开发手册》中给我们的答案:
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
1)newFixedThreadPool和newSingleThreadExecutor:
主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
2)newCachedThreadPool和newScheduledThreadPool:
主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
所以,综上情况所述,我们推荐使用 ThreadPoolExecutor 的方式进行线程池的创建,因为这种创建方式更可控,并且更加明确了线程池的运行规则,可以规避一些未知的风险。